Тема связей между заметками столь объемна, что этого слона надо есть по частям. Потому сегодня я хотел бы обсудить так называемые SOC/MOC связи. Т.е. связи, которые имеют отношение к источнику или оглавлениям. На первый взгляд, эта тема кажется простой. Но дьявол, как известно, кроется в деталях, потому приступим!
Зонке Арнес рекомендуют сразу связывать заметку с источником. Если, конечно же, идея заметки возникла в результате изучения того самого источника. Но сразу же вопрос – как упорядочить эти источники? У любого интеллектуально активного человека их набирается сотни, а то и тысячи. Классическим способом такого упорядочивания являются папки и подпапки. Потому подавляющая часть народа и хранит свои заметки в виде обычных файлов в файловой системе своего компьютера. А наводит порядки в них с помощью 2-панельных файловых менеджеров типа MC, Far или Total Commander. Мало того, не найдя привычного 2-панельного механизма в программах ZettelKasten, большинство обычных людей, на мой взгляд, сочтет метод глупым и неэффективным. В защиту двупанельного механизма могу привести мнение моего знакомого профессора-психолога. Он считает, что 2-панельный механизм идеально коррелирует с работой нашего двух-полушарного мозга.
Итак, как может выглядеть 2-панельный интерфейс работы с источниками? Да хоть вот так:
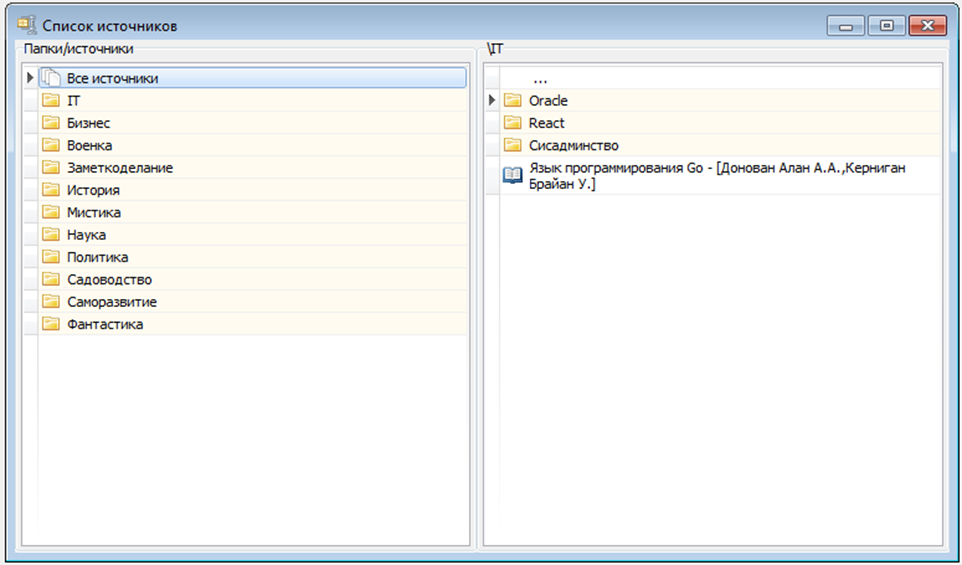
При этом очень здорово иметь возможность анализировать все источники как единый список. Например, вот так:
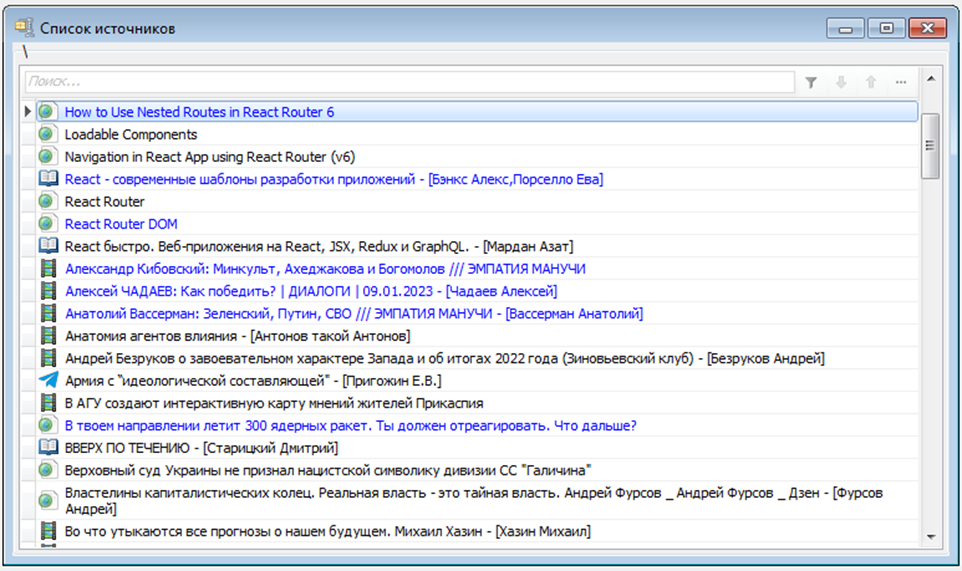
Ну и само собой быстро искать в этом списке по названию источника:
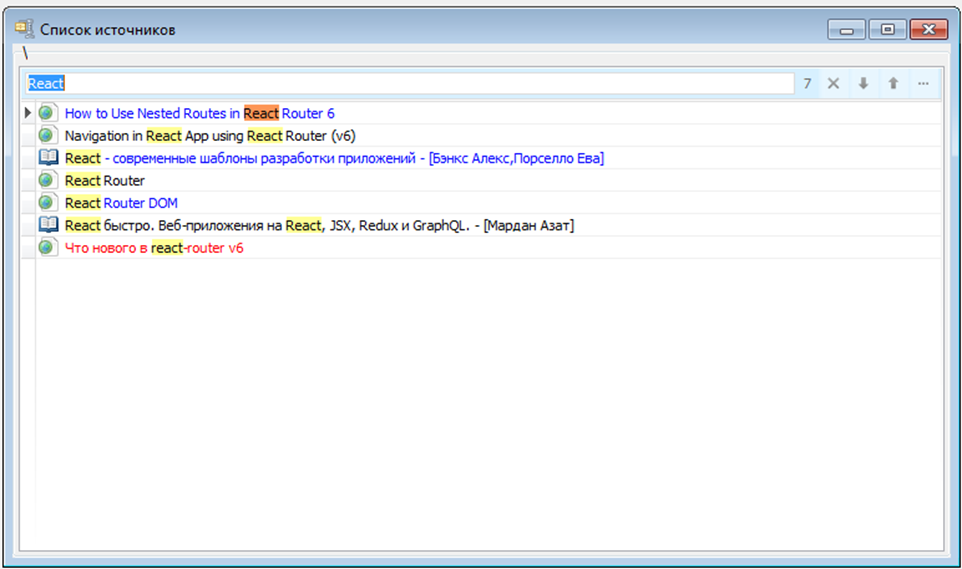
Или по ФИО автора:
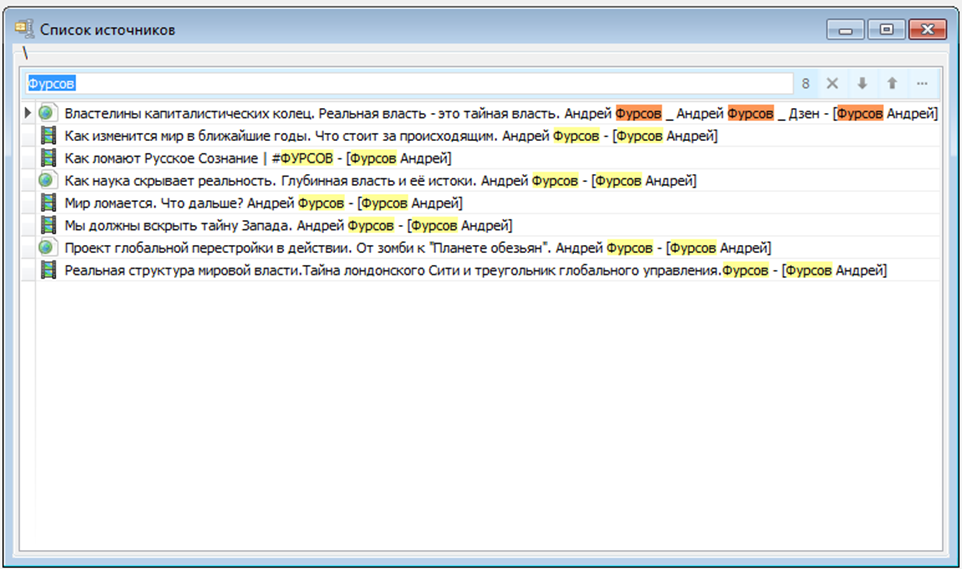
Кроме того, источники, можно разделить на две условные группы: короткие (статьи, посты) и длинные (книги, лекции). И если по «коротким» источникам обычно заносится 1-3 заметки, то по «длинным» может быть и 50 и 100 заметок. В большинстве же изученных мною программ по ZettelKasten, предлагается для каждой новой заметки указывать источник. Лично меня это выбешивает уже после 5-го тупого занесения. Вспомним, программа ZettelKasten должна приносить радость. Потому в программе должна быть возможность как-то выбрать источник по умолчанию. Тот, с которым предполагается интенсивная работа. И что все последующие заметки будут по нему, родимому. Например, это можно сделать явно. К примеру, заходить в источник и уже к нему добавлять заметку, чтобы программа сама правильно расставила SOC/MOC связи.
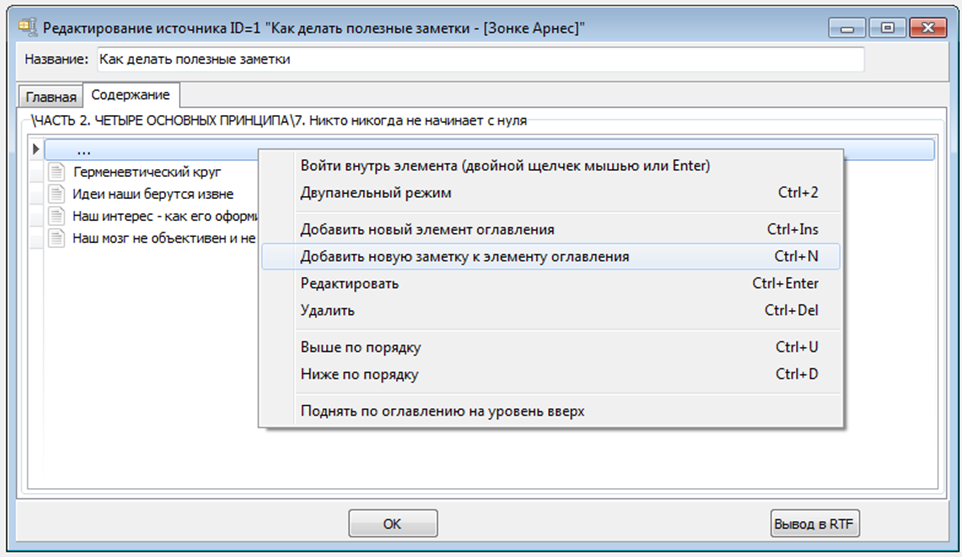
Зонке Арнес считает достаточным просто привязать свою заметку к конкретному источнику. Максимум указать № страницы. Однако, на мой взгляд, этого будет мало. Сейчас большинство авторов составляют шикарные оглавления своих книг. И грех этим было бы не воспользоваться. Привязав свою заметку не просто к источнику, а к конкретному элементу оглавления, потом можно будет и контекст быстро вспомнить. И найти нужную информацию. Например, только войдя в источник, сразу становится ясным, где сфокусированы все выписанные ранее идеи по «JavaScript для React»:
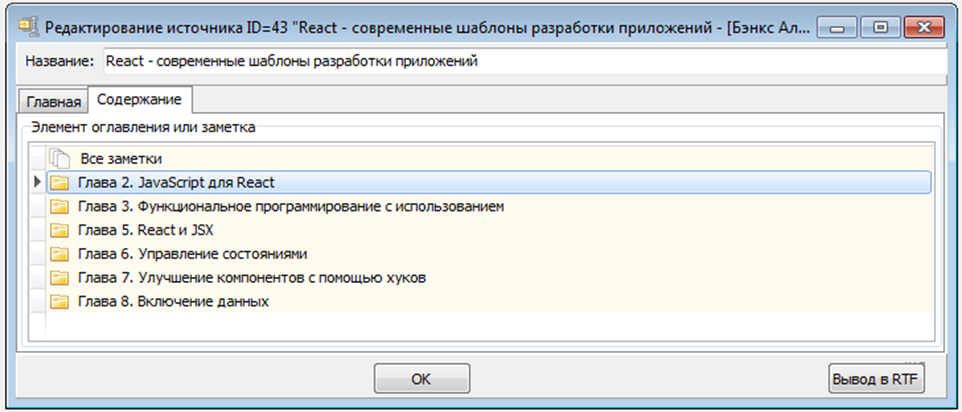
Да, лично я не дублирую все оглавление изучаемого источника. Зачем? Я вношу только те пункты содержания, по которым у меня возникают интересные идеи для заметок.
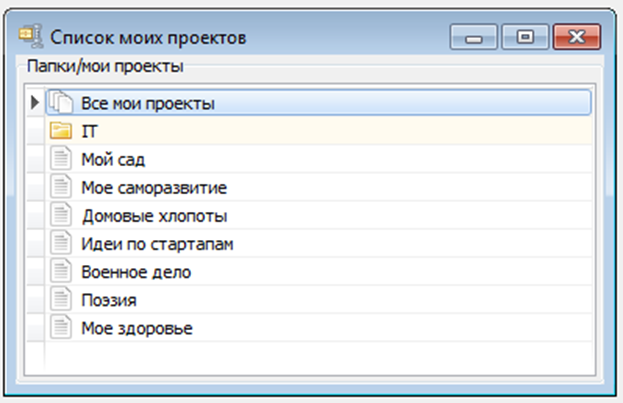
Кроме источников, Зонке Арнес предлагает регулярно создавать как бы обзорные заметки-оглавления по темам. Я называю такие заметки-концентраторы «Моими проектами». Хотя, возможно, лучше подойдет другое название. У меня на текущий момент всего 18 таких проектов:
Путем проб и ошибок выяснил, что такие концентраторы удобней всего оформлять по образу и подобию источников:
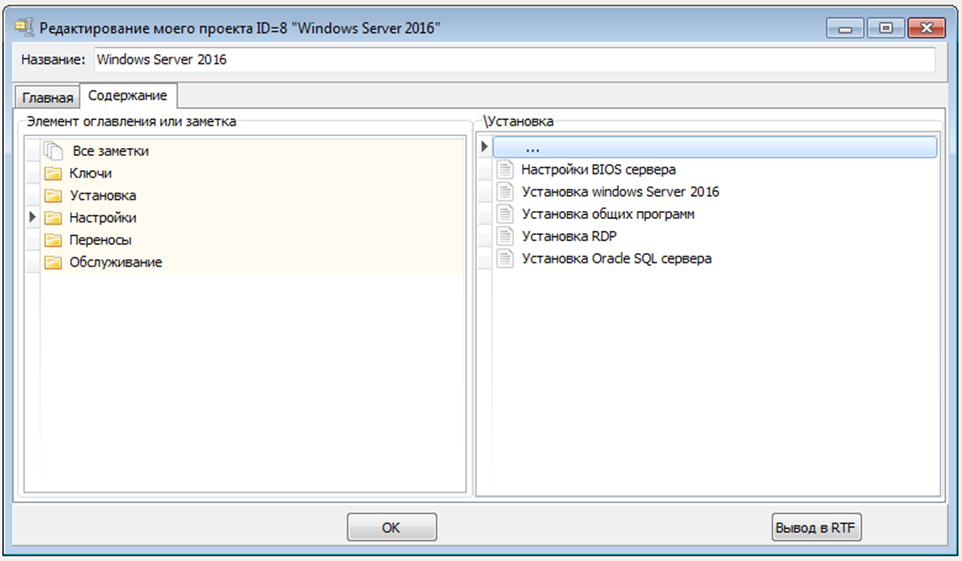
И здесь опять во всей своей красоте заиграл 2-х панельный интерфейс. Дело в том, что содержание реальной книги – уже законченный продукт. А вот оглавление такого концентратора – крайне гибкая и постоянно меняющаяся вещь. И без двупанельного подхода, на мой взгляд, никогда не добиться удобства в формировании такого оглавления.
Отдельно хочу отметить отличие от привычных файловых двупанельных программ. Сколько я таких не перепробовал, но нигде не встречал возможности ручного задания порядка, и возможности чтобы иногда папки шли после файлов. Наподобие такого:
А оно иногда бывает прям таки необходимо. Вроде бы мелочь, но, с точки зрения Зонке Арнеса, программа должна быть удобна вплоть до мелочей.
В данном посте я рассмотрел личный опыт использования SOC/MOC связывания заметок. Часть из описанных подходов родилась в результате общения на данном форуме. Но я прекрасно понимаю, что моей программе еще далеко до совершенства. Потому с радостью приму любую конструктивную критику!